田志喜研究组搭建大豆多维组学数据库
| 来源:遗传所【字号:大 中 小】
大豆(Glycine max (L.) Merr.)是世界范围内重要的粮油作物之一,其产量提升、品质改进关乎全球人口的需求和利益。21世纪后,基因组学的兴起为作物研究带来了全新的驱动力。近10年来,基因组学持续繁荣,大豆的组学研究也发生了极大的跃迁,体现在数据类型的扩展、数据维度的交叉以及数据体量的激增(图1)。因此,后基因组学时代全新的多维组学数据库的开发,将会为大豆遗传育种提供有力支持。
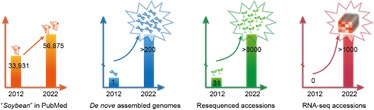
图1. 近10年间大豆数据的增长
2023年3月22日,中国科学院遗传与发育生物学研究所田志喜研究组协同北京基因组所(国家生物信息中心)章张、宋述慧研究组在Molecular Plant(DOI:10.1016/j.molp.2023.03.011)发表了题为“SoyOmics: A deeply integrated database on soybean multi-omics”的论文,以大规模基因组、变异组、表型组、转录组、泛基因组数据为基础,开发了名为SoyOmics的大豆多维组学深度整合数据库,提供了高质量的大豆组学数据检索和分析平台,为大豆研究社群提供了新的数据平台。
大豆基因组于2010年公布,其后Soybase等大豆数据库相继诞生,建立起了早期的大豆组学数据网络生态。但以现今多维组学发展的角度审视,早年的数据库框架存在诸多不足,反应在组学数据类型覆盖不全,各数据类型、功能模块间的联动性不充分等。深度整合多维组学数据,提供具备实用交互性,并且提供“一站式”分析结果的在线集成工具是当下多组学数据库开发面对的重点需求(图2)。
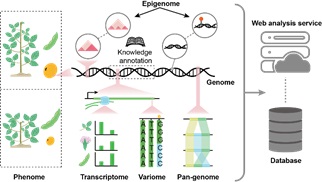
图2. 多组学构建的作物遗传全景图与数据需求
基于此,研究团队开发了面向大豆多维组学数据库:SoyOmcis。SoyOmics全面收录了大豆相关研究领域的多维组学数据,包括:29个Glyince属 Soja亚属物种及6个Glycine亚属物种的从头组装基因组;近3000份大豆种质资源的种质信息,以及来自这些材料的约3800万条SNP/INDEL变异数据;针对115个表型多年多点测定的约2万7千条表型记录;来自29个Soja亚属物种比较基因组的约55万条结构变异数据,以及基于结构变异构建的图泛基因组;自泛基因组种质取样的覆盖9~28个组织/时期的转录组数据数据;取样自50个种质资源的甲基化测序数据;以及GenoBaits Soy40K大豆芯片数据(图2)。此外,数据库还收录了大豆中已报道的QTL、GWAS位点和近200个功能明确的基因注释信息,便于在搜索中提供更丰富的参考信息。
研究团队将这些数据整合为6个基础模块,并且搭建了各模块间的联动架构,可以满足用户对于基因组区段特征、基因、变异位点、种质、表型等相关知识的检索、分类和统合需求。在此基础上,研究团队开发了多个实用的“一站式”分析模块,支撑实现GWAS分析、表达模式分析、单倍型分析、基因组坐标转换、图泛基因组可视化等分析操作。以上共同组成SoyOmics的基本功能群(图2)。
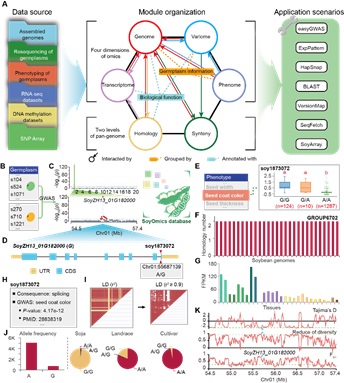
图3. SoyOmics框架介绍与应用实例
综上,SoyOmics是在后基因组学时代推出的,面向新需求、新数据组织形式开发的大豆多维组学数据库。该数据库具备多维组学数据间的深度关联性、用户的高度可交互性以及分析场景的高覆盖性,预期能为大豆遗传学及育种研究提供基础的数据支撑和全新的观察视角。
中科院遗传发育所田志喜研究员为该论文通讯作者,中科院北京基因组所(国家生物信息中心)章张研究员、宋述慧研究员为该论文的共同通讯作者,中科院遗传发育所刘羽诚博士,中科院北京基因组所(国家生物信息中心)博士研究生张阳、刘晓楠,中科院遗传发育所申妍婷副研究员为该论文共同第一作者。该研究得到了中科院先导项目、科技创新2030-重大项目、国家自然科学基金、国家重点研发计划、博士后创新人才计划等项目的资助。

